

Service存在的意义
服务发现(pod) Service通过label-selector 关联Pod
定义一组Pod的访问策略(4层负载均衡)
三种常用类型
(1)ClusterIP(集群内部使用)
默认方式,分配一个稳定的IP地址,即VIP,只能在集群内部访问
(2)NodePort(对外暴露应用)
在每个节点启用一个端口来暴露服务,可以在集群外部访问,通过NodeIP:NodePort访问
端口范围:30000~32767
(3)LoadBalancer(对外暴露应用,适用于公有云)
与NodePort类似,在每个节点启用一个端口来暴露服务。除此之外,K8s请求底层云平台的负载均衡器,把每个[Node IP]:[NodePort]作为后端添加进去
虚拟 IP 和 Service 代理
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。 kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式
service 与 kube-proxy
kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。
service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化
服务发现作用
因为Pod存在生命周期,有销毁,有重建,无法提供一个固定的访问接口给客户端。并且可能同时存在多个副本的。
因此服务发现就是为Pod对象提供了一个固定、统一的访问接口和负载均衡能力.
服务发现方式
DNS: 可以通过cluster add-on的方式轻松的创建KubeDNS来对集群内的Service进行服务发现,这也是k8s官方强烈推荐的方式
为了让Pod中的容器可以使用kube-dns来解析域名k8s会修改容器的/etc/resolv.conf配置
k8s服务发现原理
endpoint是k8s集群中的一个资源对象存储在etcd中用来记录一个service对应的所有pod的访问地址。
service配置selector endpoint controller才会自动创建对应的endpoint对象: 否则不会生成endpoint对象
例如k8s集群中创建一个名为k8s-classic-1113-d3的service就会生成一个同名的endpoint对象
kubectl get ep
service 负载分发策略
service 负载分发策略有两种
RoundRobin: 轮询模式即轮询将请求转发到后端的各个pod上 默认模式
SessionAffinity: 基于客户端IP地址进行会话保持的模式第一次客户端访问后端某个pod之后的请求都转发到这个pod上。
service selector
service通过selector和pod建立关联。
k8s会根据service关联到pod的podIP信息组合成一个endpoint。
若service定义中没有selector字段service被创建时endpoint controller不会自动创建endpoint
endpoint controller是k8s集群控制器的其中一个组件其功能如下:
负责生成和维护所有endpoint对象的控制器
负责监听service和对应pod的变化
监听到service被删除则删除和该service同名的endpoint对象
监听到新的service被创建则根据新建service信息获取相关pod列表然后创建对应endpoint对象
监听到service被更新则根据更新后的service信息获取相关pod列表然后更新对应endpoint对象
监听到pod事件则更新对应的service的endpoint对象将podIp记录到endpoint中
Service实现思路
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式。
kube-proxy 这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)
负载均衡
kube-proxy负责service的实现即实现了k8s内部从pod到service和外部从node port到service的访问。
kube-proxy采用iptables(默认)或LVS的方式配置负载均衡基于iptables的kube-proxy的主要职责包括两大块: 一块是侦听service更新事件并更新service相关的iptables规则一块是侦听endpoint更新事件更新endpoint相关的iptables规则(: 如 KUBE-SVC-链中的规则: 然后将包请求转入endpoint对应的Pod。如果某个service尚没有Pod创建那么针对此service的请求将会被drop掉。
kube-proxy的架构如下:
Kube-proxy 是 kubernetes 工作节点上的一个网络代理组件,运行在每个节点上
Kube-proxy维护节点上的网络规则,实现了Kubernetes Service 概念的一部分 。它的作用是使发往 Service 的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod
工作原理
kube-proxy 监听 API server 中 资源对象的变化情况,包括以下三种:
- service
- endpoint/endpointslices
- node
然后根据监听资源变化操作代理后端来为服务配置负载均衡。
如果你的 kubernetes 使用EndpointSlice,那么kube-proxy会监听EndpointSlice,否则会监听Endpoint。
如果你启用了服务拓扑,那么 kube-proxy 也会监听 node 信息 。服务拓扑(Service Topology)可以让一个服务基于集群的 Node 拓扑进行流量路由。 例如,一个服务可以指定流量是被优先路由到一个和客户端在同一个 Node 或者在同一可用区域的端点。
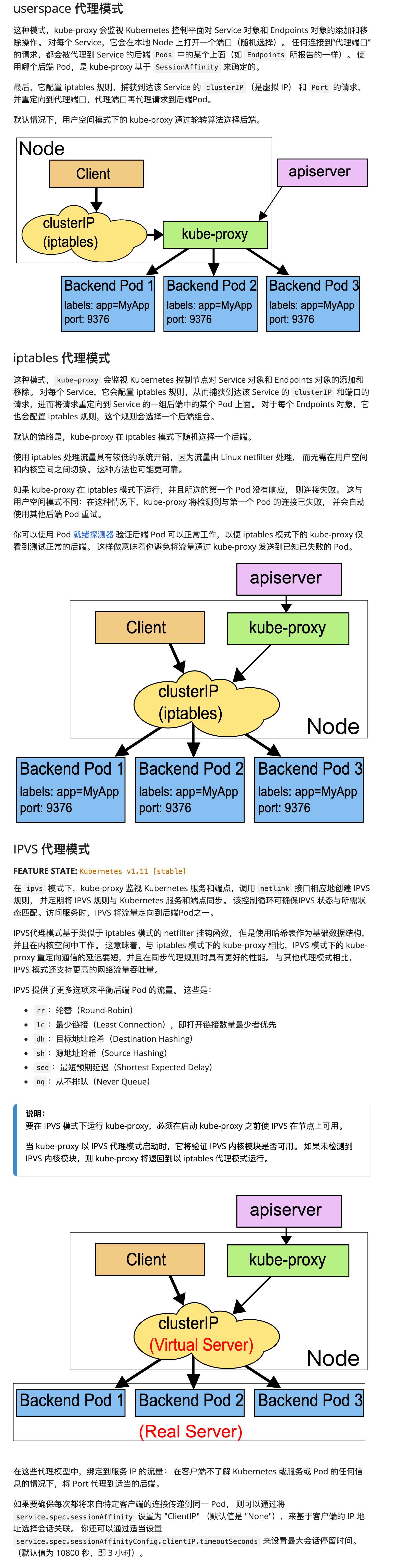
代理模式
目前 Kube-proxy 支持4中代理模式:
- userspace
- iptables
- ipvs
- kernelspace
其中 kernelspace 专用于windows,userspace 是早期版本的实现,
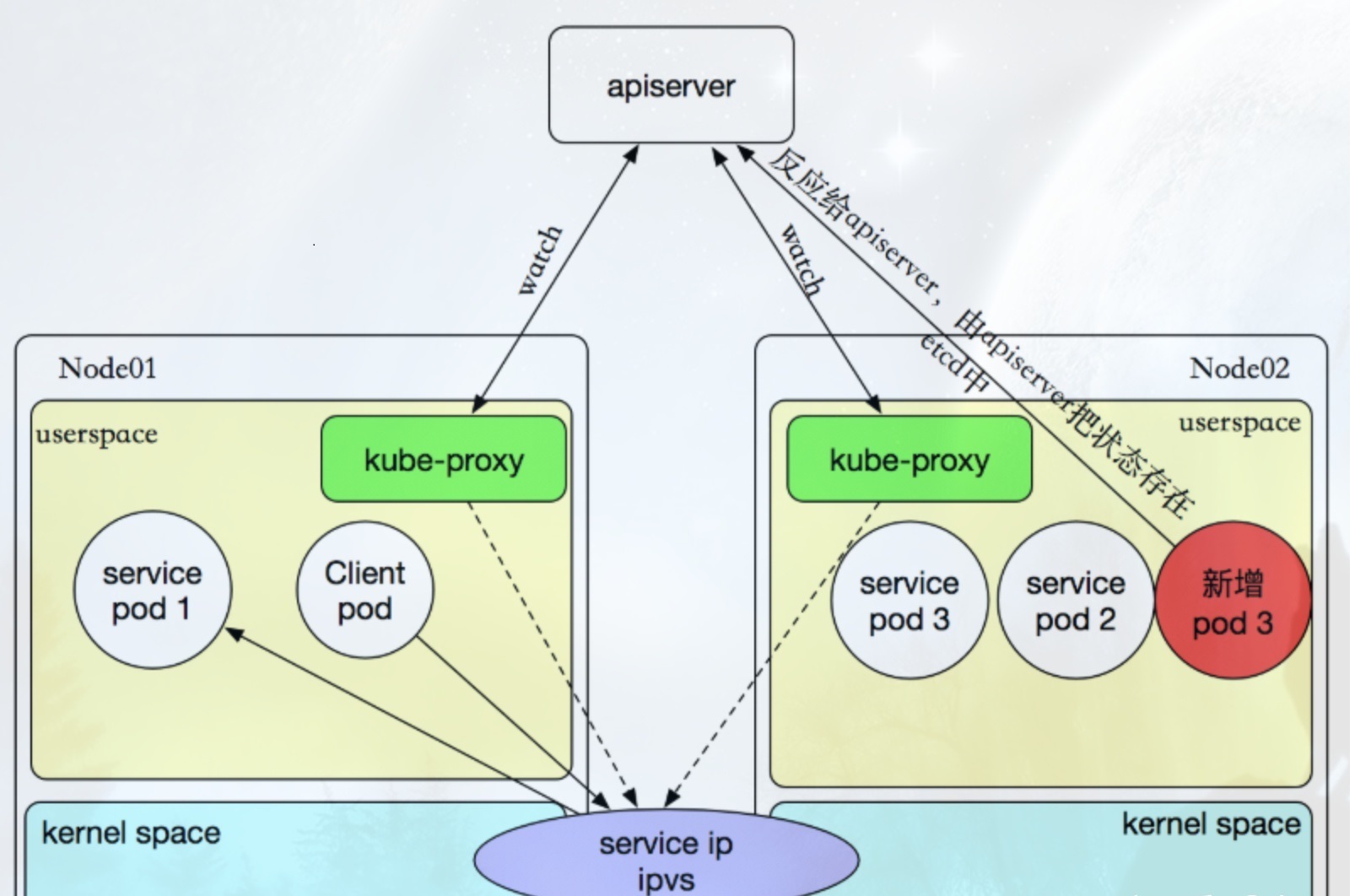
kube-proxy都通过watch的方式监控着kube-APIServer写入etcd中关于Pod的最新状态信息,
它一旦检查到一个Pod资源被删除了 或 新建,它将立即将这些变化,反应再iptables 或 ipvs规则中,以便
iptables和ipvs在调度Clinet Pod请求到Server Pod时,不会出现Server Pod不存在的情况
Userspace方式: Client Pod要访问Server Pod时,它先将请求发给本机内核空间中的service规则,由它再将请求转给监听在指定套接字上的kube-proxy,kube-proxy处理完请求,并分发请求到指定Server Pod后,再将请求递交给内核空间中的service,由service将请求转给指定的Server Pod

iptables模型:此工作方式是直接由内核中的iptables规则,接受Client Pod的请求,并处理完成后,直接转发给指定ServerPod.
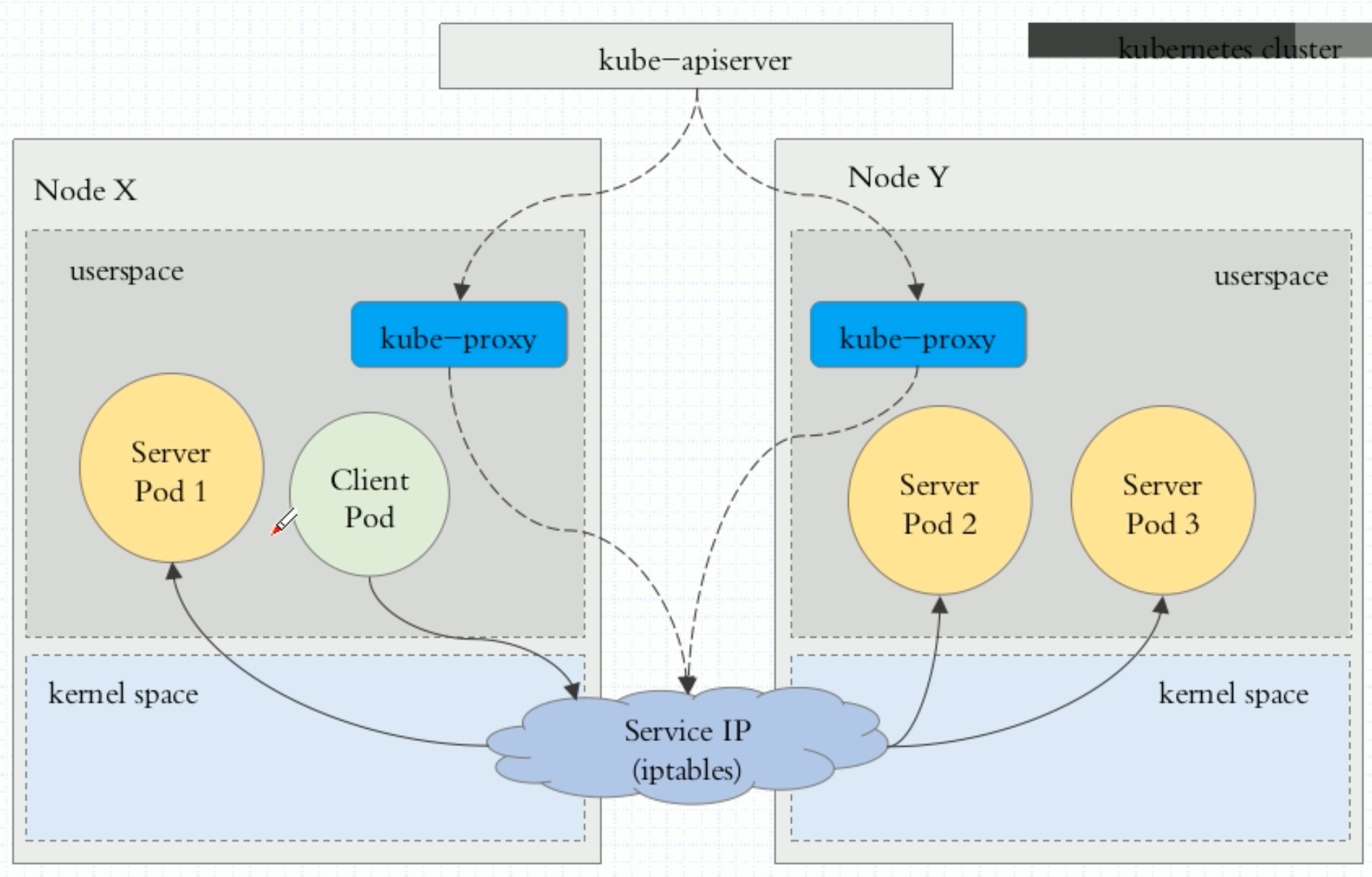
ipvs模型: 它是直接有内核中的ipvs规则来接受Client Pod请求,并处理该请求,再有内核封包后,直接发给指定的Server Pod

自k8s1.1以后,service默认使用ipvs规则,若ipvs没有被激活,则降级使用iptables规则. 但在1.1以前,service
使用的模式默认为userspace.
官方文档
iptables
iptables -S -tnat |grep KUBE-SERVICES
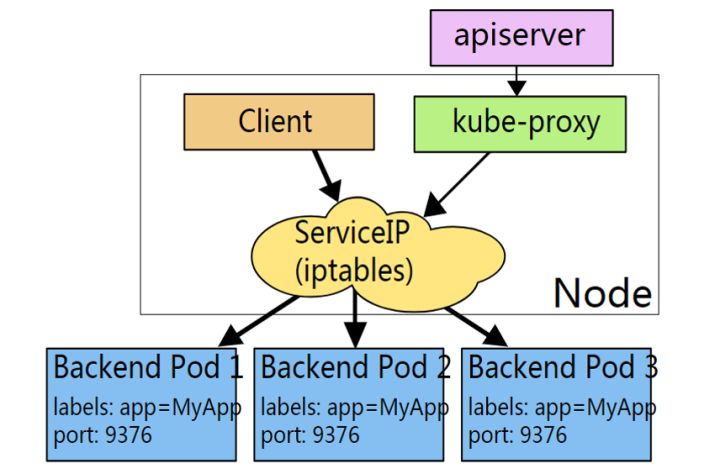
在iptables模式下,kube-proxy将规则附加到“ NAT预路由”钩子上,以实现其NAT和负载均衡功能。这种方法很简单,使用成熟的内核功能,并且可以与通过iptables实现网络策略的组件“完美配合”。
客户端IP请求时,直接请求本地内核service ip,根据iptables的规则直接将请求转发到到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。iptables代理模式由Kubernetes 1.1版本引入,自1.2版本开始成为默认类型。
ipvs
kubernetes自1.9-alpha版本引入了ipvs代理模式,自1.11版本开始成为默认设置。客户端IP请求时到达内核空间时,根据ipvs的规则直接分发到各pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:
轮询调度 - lc:最小连接数
dh:目标哈希sh:源哈希sed:最短期望延迟nq:不排队调度
